VitaLITy: Promoting Serendipitous Discovery of Academic Literature with Transformers & Visual Analytics
VitaLITy: Promoting Serendipitous Discovery of Academic Literature with Transformers & Visual Analytics
Abstract
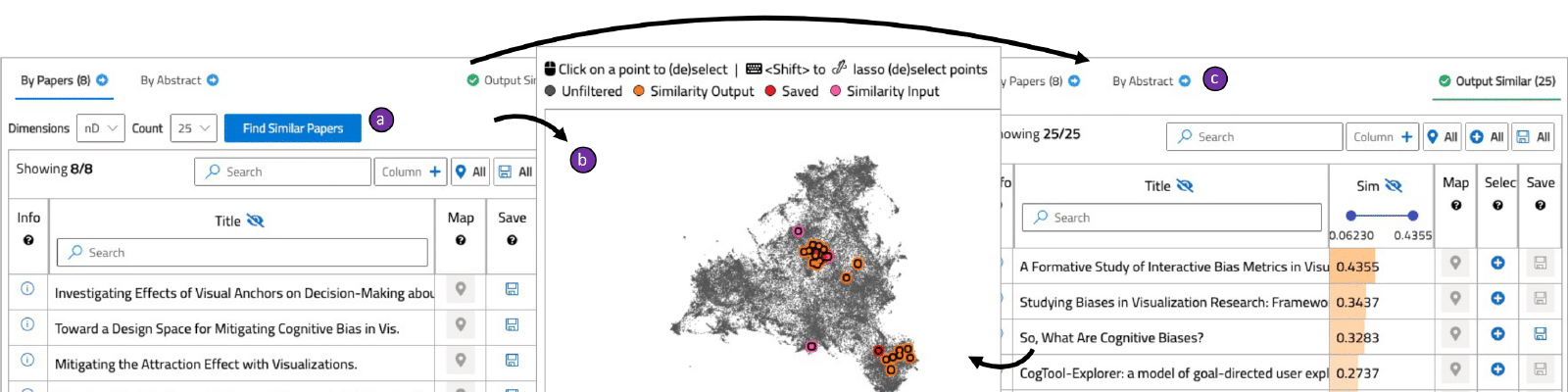
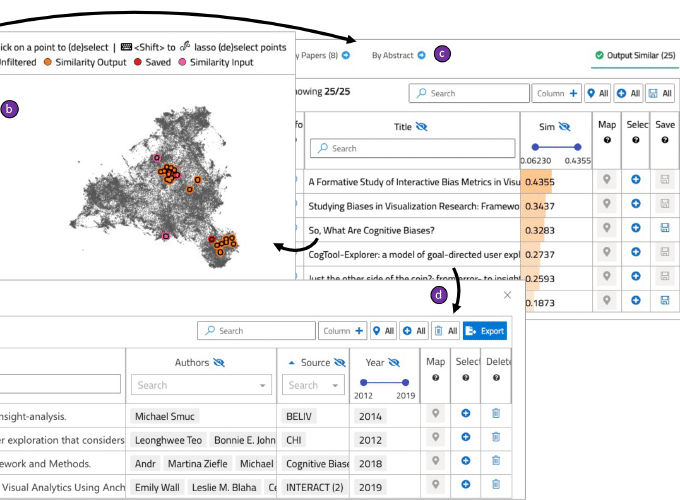
There are a few prominent practices for conducting reviews of academic literature, including searching for specific keywords on Google Scholar or checking citations from some initial seed paper(s). These approaches serve a critical purpose for academic literature reviews, yet there remain challenges in identifying relevant literature when similar work may utilize different terminology (e.g., mixed-initiative visual analytics papers may not use the same terminology as papers on model-steering, yet the two topics are relevant to one another). In this paper, we introduce a system, VitaLITy, intended to complement existing practices. In particular, VitaLITy promotes serendipitous discovery of relevant literature using transformer language models, allowing users to find semantically similar papers in a word embedding space given (1) a list of input paper(s) or (2) a working abstract. VitaLITy visualizes this document-level embedding space in an interactive 2-D scatterplot using dimension reduction. VitaLITy also summarizes meta information about the document corpus or search query, including keywords and co-authors, and allows users to save and export papers for use in a literature review. We present qualitative findings from an evaluation of VitaLITy, suggesting it can be a promising complementary technique for conducting academic literature reviews. Furthermore, we contribute data from 38 popular data visualization publication venues in VitaLITy, and we provide scrapers for the open-source community to continue to grow the list of supported venues.